PSoC® 3: CY8C32 Family
Data Sheet
4.4.2 DMA Features
shown in Table 4-7 after the CPU and DMA priority levels 0 and
1 have satisfied their requirements.
Table 4-7. Priority Levels
24 DMA channels
Each channel has one or more transaction descriptors (TDs)
to configure channel behavior. Up to 128 total TDs can be
defined
Priority Level
% Bus Bandwidth
0
1
2
3
4
5
6
7
100.0
100.0
50.0
25.0
12.5
6.2
TDs can be dynamically updated
Eight levels of priority per channel
Anydigitallyroutablesignal, theCPU, oranotherDMAchannel,
can trigger a transaction
Each channel can generate up to two interrupts per transfer
Transactions can be stalled or canceled
3.1
Supports transaction size of infinite or 1 to 64k bytes
TDs may be nested and/or chained for complex transactions
1.5
When the fairness algorithm is disabled, DMA access is granted
based solely on the priority level; no bus bandwidth guarantees
are made.
4.4.3 Priority Levels
The CPU always has higher priority than the DMA controller
when their accesses require the same bus resources. Due to the
system architecture, the CPU can never starve the DMA. DMA
channels of higher priority (lower priority number) may interrupt
current DMA transfers. In the case of an interrupt, the current
transfer is allowed to complete its current transaction. To ensure
latency limits when multiple DMA accesses are requested
simultaneously, a fairness algorithm guarantees an interleaved
minimum percentage of bus bandwidth for priority levels 2
through 7. Priority levels 0 and 1 do not take part in the fairness
algorithm and may use 100 percent of the bus bandwidth. If a tie
occurs on two DMA requests of the same priority level, a simple
round robin method is used to evenly share the allocated
bandwidth. The round robin allocation can be disabled for each
DMA channel, allowing it to always be at the head of the line.
Priority levels 2 to 7 are guaranteed the minimum bus bandwidth
4.4.4 Transaction Modes Supported
The flexible configuration of each DMA channel and the ability to
chain multiple channels allow the creation of both simple and
complex use cases. General use cases include, but are not
limited to:
4.4.4.1 Simple DMA
In a simple DMA case, a single TD transfers data between a
source and sink (peripherals or memory location). The basic
timing diagrams of DMA read and write cycles are shown in
Figure 4-1. For more description on other transfer modes, refer
to the Technical Reference Manual.
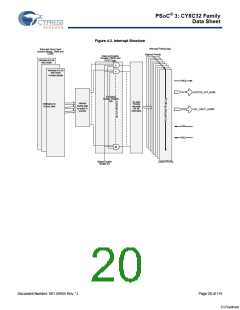
Figure 4-1. DMA Timing Diagram
ADDRESS Phase
DATA Phase
ADDRESS Phase
DATA Phase
CLK
CLK
ADDR 16/32
WRITE
ADDR 16/32
A
B
A
B
WRITE
DATA
DATA (A)
DATA (A)
DATA
READY
READY
Basic DMA Read Transfer without wait states
Basic DMA Write Transfer without wait states
4.4.4.2 Auto Repeat DMA
data previously received in the other buffer. In its simplest form,
this is done by chaining two TDs together so that each TD calls
the opposite TD when complete.
Auto repeat DMA is typically used when a static pattern is
repetitively read from system memory and written to a peripheral.
This is done with a single TD that chains to itself.
4.4.4.4 Circular DMA
4.4.4.3 Ping Pong DMA
Circular DMA is similar to ping pong DMA except it contains more
than two buffers. In this case there are multiple TDs; after the last
TD is complete it chains back to the first TD.
A ping pong DMA case uses double buffering to allow one buffer
to be filled by one client while another client is consuming the
Document Number: 001-56955 Rev. *J
Page 17 of 119
[+] Feedback

 CYPRESS [ CYPRESS ]
CYPRESS [ CYPRESS ]