TMS320C6678
Multicore Fixed and Floating-Point Digital Signal Processor
SPRS691D—April 2013
www.ti.com
2.2 DSP Core Description
The C66x Digital Signal Processor (DSP) extends the performance of the C64x+ and C674x DSPs through
enhancements and new features. Many of the new features target increased performance for vector processing. The
C64x+ and C674x DSPs support 2-way SIMD operations for 16-bit data and 4-way SIMD operations for 8-bit data.
On the C66x DSP, the vector processing capability is improved by extending the width of the SIMD instructions.
C66x DSPs can execute instructions that operate on 128-bit vectors. For example the QMPY32 instruction is able to
perform the element-to-element multiplication between two vectors of four 32-bit data each. The C66x DSP also
supports SIMD for floating-point operations. Improved vector processing capability (each instruction can process
multiple data in parallel) combined with the natural instruction level parallelism of C6000 architecture (e.g
execution of up to 8 instructions per cycle) results in a very high level of parallelism that can be exploited by DSP
programmers through the use of TI's optimized C/C++ compiler.
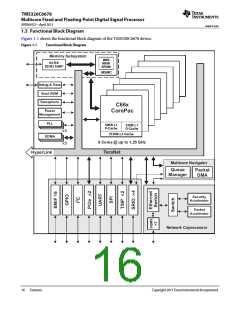
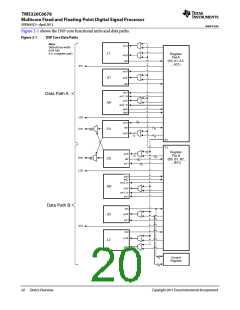
The C66x DSP consists of eight functional units, two register files, and two data paths as shown in Figure 2-1. The
two general-purpose register files (A and B) each contain 32 32-bit registers for a total of 64 registers. The
general-purpose registers can be used for data or can be data address pointers. The data types supported include
packed 8-bit data, packed 16-bit data, 32-bit data, 40-bit data, and 64-bit data. Multiplies also support 128-bit data.
40-bit-long or 64-bit-long values are stored in register pairs, with the 32 LSBs of data placed in an even register and
the remaining 8 or 32 MSBs in the next upper register (which is always an odd-numbered register). 128-bit data
values are stored in register quadruplets, with the 32 LSBs of data placed in a register that is a multiple of 4 and the
remaining 96 MSBs in the next 3 upper registers.
The eight functional units (.M1, .L1, .D1, .S1, .M2, .L2, .D2, and .S2) are each capable of executing one instruction
every clock cycle. The .M functional units perform all multiply operations. The .S and .L units perform a general set
of arithmetic, logical, and branch functions. The .D units primarily load data from memory to the register file and
store results from the register file into memory.
Each C66x .M unit can perform one of the following fixed-point operations each clock cycle: four 32 × 32 bit
multiplies, sixteen 16 × 16 bit multiplies, four 16 × 32 bit multiplies, four 8 × 8 bit multiplies, four 8 × 8 bit multiplies
with add operations, and four 16 × 16 multiplies with add/subtract capabilities. There is also support for Galois field
multiplication for 8-bit and 32-bit data. Many communications algorithms such as FFTs and modems require
complex multiplication. Each C66x .M unit can perform one 16 × 16 bit complex multiply with or without rounding
capabilities, two 16 × 16 bit complex multiplies with rounding capability, and a 32 × 32 bit complex multiply with
rounding capability. The C66x can also perform two 16 × 16 bit and one 32 × 32 bit complex multiply instructions
that multiply a complex number with a complex conjugate of another number with rounding capability.
Communication signal processing also requires an extensive use of matrix operations. Each C66x .M unit is capable
of multiplying a [1 × 2] complex vector by a [2 × 2] complex matrix per cycle with or without rounding capability.
A version also exists allowing multiplication of the conjugate of a [1 × 2] vector with a [2 × 2] complex matrix.
Each C66x .M unit also includes IEEE floating-point multiplication operations from the C674x DSP, which includes
one single-precision multiply each cycle and one double-precision multiply every 4 cycles. There is also a
mixed-precision multiply that allows multiplication of a single-precision value by a double-precision value and an
operation allowing multiplication of two single-precision numbers resulting in a double-precision number. The
C66x DSP improves the performance over the C674x double-precision multiplies by adding a instruction allowing
one double-precision multiply per cycle and also reduces the number of delay slots from 10 down to 4. Each C66x
.M unit can also perform one the following floating-point operations each clock cycle: one, two, or four
single-precision multiplies or a complex single-precision multiply.
The .L and .S units can now support up to 64-bit operands. This allows for new versions of many of the arithmetic,
logical, and data packing instructions to allow for more parallel operations per cycle. Additional instructions were
added yielding performance enhancements of the floating point addition and subtraction instructions, including the
ability to perform one double precision addition or subtraction per cycle. Conversion to/from integer and
single-precision values can now be done on both .L and .S units on the C66x. Also, by taking advantage of the larger
18
Device Overview
Copyright 2013 Texas Instruments Incorporated

 TI [ TEXAS INSTRUMENTS ]
TI [ TEXAS INSTRUMENTS ]